Data Centres Water Requirement. From Cooling To Energy Consumption, Are They Sustainable?
A data center is a dedicated space in a building that houses computer systems and related components like storage and telecommunication systems. It comprises backup components and robust infrastructure for information exchange, power supply, security devices, and environmental control systems like fire suppression and air conditioning systems.
How Does It Work?
A data centre consists of virtual or physical servers (or robust computer systems) connected externally and internally through communication and networking equipment to store digital information and transfer it. It contains several components to serve different purposes:
Networking: It refers to the interconnections between a data center’s components and the outside world. It includes routers, app delivery controllers, firewalls, switches, etc.
Storage: An organization’s data is stored in data centres. The components for storage are tape drives, hard disk drives, solid-state drives (SSDs) with backups, etc.
Compute: It refers to the processing power and memory required to run applications. It is supplied through powerful computers to run applications.
Types of Data Centres
You can come across different types of data centres based on how they are owned, technologies used, and energy efficiency. Some of the main types of data centres that organizations use is:
Managed Data Centres
In a managed data centre, a third-party service provider offers computing, data storage, and other related services to organizations directly to help them run and manage their IT operations. The service provider deploys, monitors, and manages this data centre model, offering the features via a managed platform.
You can source the managed data centre services from a colocation facility, cloud data centres, or a fixed hosting site. A managed data centre can either be partially or fully managed. If it’s partially managed, the organization will have administration control over the data centre service and implementation. However, if it’s fully managed, all the back-end data and technical details are administered and controlled by the service provider.
Suitable for: The ideal users of managed data centres are medium to large businesses.
Benefits: You do not have to deal with regular maintenance, security, and other aspects. The data centre provider is responsible for maintaining network services and components, upgrading system-level programs and operating systems, and restoring service if anything goes wrong.
Enterprise Data Centres
An enterprise data centre refers to a private facility that supports the IT operations of a single organization. It can be situated at a site off-premises or on-premises based on their convenience. This type of data centre may consist of multiple data centres located at different global locations to support an organization’s key functions.
For example, if a business has customers from different global regions, they can set up data centres closer to their customers to enable faster service.
Enterprise data centres can have sub-data centres, such as:
Intranet controls data and applications within the main enterprise data centre. Enterprise uses the data for their research & development, marketing, manufacturing, and other functions.
Extranet performs business-to-business transactions inside the data centre network. The company accesses the services through VPNs or private WANs. The internet data centre is used to support servers and devices needed to run web applications.
Suitable for: As the name suggests, enterprise data centres are ideal for enterprises with global expansion and distinguished network requirements. It’s because they have enough revenue to support their data centres at multiple locations.
Benefits: It’s beneficial for businesses as it allows them to track critical parameters like power and bandwidth utilization and helps update their applications and systems. It also helps the companies understand their needs more and scale their capacities accordingly.
However, building enterprise data centre facilities needs heavy investments, maintenance needs, time, and effort.
Colocation Data Centres
A colocation data centre or “colo” is a facility that a business can rent from a data centre owner to enable IT operations to support applications, servers, and devices. It is becoming increasingly popular these days, especially for organizations that don’t have enough resources to build and manage a data centre of their own but still need it anyway. In a colo, you may use features and infrastructure such as building, security, bandwidth, equipment, and cooling systems. It helps connect network devices to different network and telecommunication service providers. The popularity of colocation facilities grew around the 2000s when organizations wanted to outsource some operations but with certain controls. Even if you rent some space from a data centre provider, your employees can still work within that space and even connect with other company servers.
Suitable for: Colocation data centres are suitable for medium to large businesses.
Benefits: There are several benefits that you can avail yourself from a colocation server, such as:
Scalability to support your business growth; you can add or remove servers and devices easily without hassles.
You will have the option to host the data centre at different global locations closest to your customers to offer the best experience.
Colocation data centres offer high reliability with powerful servers, computing power, and redundancy.
It also saves you money as you don’t have to build a large data centre from scratch at multiple locations. You can just rent it out based on your budget and present needs.
You don’t need to handle the data centre maintenance such as device installation, updates, power management, and other processes.
Cloud Data Centres
One of the most popular types of data centre these days is the cloud data centre. In this type, a cloud service provider runs and manages the data centre to support business applications and systems. It’s like a virtual data centre with even more benefits than colocation data centres.
The popular cloud service providers are Amazon AWS, Google, Microsoft Azure, Salesforce, etc. When data uploads in the cloud servers, the cloud service providers duplicate and fragment this data across multiple locations to ensure it’s never lost. They also back up your data, so you don’t lose it even if something goes wrong.
Now, cloud data centres can be of two types – public and private.
Public cloud providers like AWS and Azure offer resources through the internet to the public. Private cloud service providers offer customized cloud services. They give you singular access to private clouds (their cloud environment). Example: Salesforce CRM.
Suitable for: Cloud data centres are ideal for almost any organization of any type or scale.
Benefits: There are many benefits of using cloud data centres compared to physical or or-premise data centres, including:
It’s cost-effective as you don’t have to invest heavily in building a data centre from scratch. You just have to pay for the service you utilize and as long as you need it. You are free from maintenance requirements. They will take care of everything, from installing systems, upgrading software, and maintaining security to backups and cooling. It offers a flexible pricing plan. You can go for a monthly subscription and be aware of your expenditure in an easier way.
Edge Data Centres
The most recent of all, edge data centres are still in the development stage. They are smaller data centre facilities situated closer to the customers an organization serves. It utilizes the concept of edge computing by bringing the computation closer to systems that generate data to enable faster operations. Edge data centres are characterized by connectivity and size, allowing companies to deliver services and content to their local users at a greater speed and with minimal latency. They are connected to a central, large data centre or other data centres. In the future, edge data centres can support autonomous vehicles and IoT to offer higher processing power and improve the consumer experience.
Suitable for: Small to medium-sized businesses
Benefits: The benefits of using an edge data centre are:
An edge data centre can distribute high traffic loads efficiently. It can cache requested content and minimize the response time for a user request. It can also help increase network reliability by distributing traffic loads efficiently. The data centre offers a superb performance by placing computation closer to the source.
Hyperscale Data Centres
Hyperscale data centres are massive and house thousands of servers. They are designed to be highly scalable by adding more devices and equipment or increasing system power. The demand for hyper scale data centres is increasing with increasing data generation. Businesses now deal with an enormous amount of data, which begins to rise. Hence, to store and manage this sort of data, they need a giant data centre, and hyper scale seems to be the right choice for it.
Suitable for: Hyperscale data centres are best for large enterprises with massive amounts of data to store and manage.
Benefits: Initially, the data centre providers designed hyper scale data centres for large public cloud service providers. Although they can build it themselves, renting a hyper scale data centre comes with a lot of benefits:
It offers more flexibility; companies can scale up or down based on their current needs without any difficulties.
Increased speed to market so they can delight their customers with the best services. Freedom from maintenance needs, so they don’t waste time in repetitive work and dedicate that time to innovation. Other than these five main types of data centres, you may come across others as well. Let’s have a quick look at them.
Carrier hotels are the main internet exchange points for the entire data traffic belonging to a specific area. Carrier hotels focus on more fibre and telecom providers compared to a common colo. They are usually located downtown with a mature fibre infrastructure. However, creating a dense fibre system like this takes a great deal of effort and time, which is why they are rare. For example, One Wilshire in Los Angeles has 200+ carriers in the building to supply connectivity to the entire traffic coming from the US West Coast.
Microdata centre: It’s a condensed version of the edge data centre. It can be smaller, like an office room, to handle the data processing in a specific location.
Traditional data centres: They consisted of multiple servers in racks, performing different tasks. If you need more redundancy to manage your critical apps, you can add more servers to this rack. Starting around the 1990s, in this infrastructure, the service provider acquires, deploys, and maintains a server.
Over time, they add more servers to facilitate more capabilities. It needs monitoring the operating systems using monitoring tools, which requires a certain level of expertise. In addition, it requires patching and updating, and verifying them for security. All these require heavy investments, not to mention the powering and cooling cost is added extra.
Modular data centres: It’s a portable data centre, meaning you can deploy it at a place where you need data capacity. It contains modules and components offering scalability in addition to power and cooling capabilities. You can add modules, combine them with other modules or integrate them into a data centre.
Modular data centres can be of two types:
Containerized or portable: data centres arrange equipment into a shipping container that gets transported to a particular location. It has its own cooling systems.
Another type of modular data centre arranges equipment or devices into a capacity with prefabricated components. These components are quick to build on a location and added for more capacity.
What Are the Data Centre Tiers?
Another way of classifying data centres based on uptime and reliability is by data centre tiers. The Uptime Institute developed it during the 1990s, and there are 4 data centre tiers. Let us understand them.
Tier 1: A tier one data centre has “basic capacity” and includes a UPS. It has fewer components for redundancy and backup and a single path for cooling and power. It also involves higher downtime and may lack energy efficiency systems. It offers a minimum of 99.671% uptime, which means 28.8 hours of downtimes yearly.
Tier 2: A tier two data centre has “redundant capacity” and offers more components for redundancy and backup than tier 1. It also has a singular path for cooling and power. They are generally private data centres, and they also lack energy efficiency. Tier 2 data centres can offer a minimum of 99.741% uptime, which means 22 hours downtimes yearly.
Tier 3: A tier three data centre is “concurrently maintainable,” ensuring any component is safe to remove without impacting the process. It has different paths for cooling and power to help maintain and update the systems.
Tier 3 data centres have redundant systems to limit operational errors and equipment failure. They utilize UPS systems that supply power continuously to servers and backup generators. Therefore, they offer a minimum of 99.982% uptime, which means 1.6 hours of downtimes yearly and N+1 redundancy, higher than tiers 1 and 2.
Tier 4: A tier four data centre is “fault-tolerant” and allows a production capacity to be protected from any failure type. It requires twice the number of components, equipment, and resources to maintain a continuous flow of service even during disruptions.
Critical business operations from organizations that cannot afford downtimes use tier 4 data centres to offer the highest level of redundancy, uptime, and reliability. A tier 4 data centre provides a minimum of 99.995% uptime, which means 0.4 hours of annual downtime and 2N redundancy, which is superb.
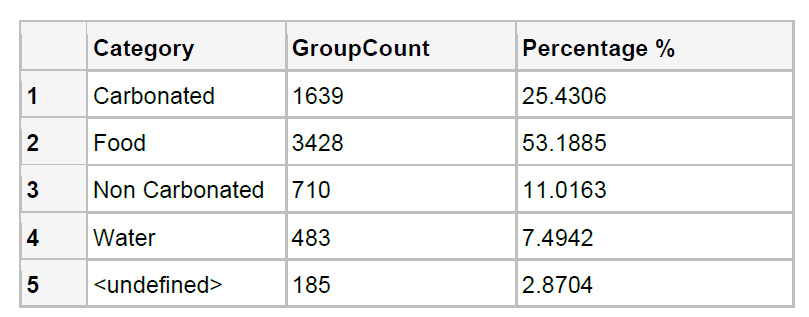
Data centre water use
Total water consumption in the USA in 2015 was 1218 billion litres per day, of which thermoelectric power used 503 billion litres, irrigation used 446 billion litres and 147 billion litres per day went to supply 87% of the US population with potable water. Data centres consume water across two main categories: indirectly through electricity generation (traditionally thermoelectric power) and directly through cooling. In 2014, a total of 626 billion litres of water use was attributable to US data centres. This is a small proportion in the context of such high national figures; however, data centres compete with other users for access to local resources. A medium-sized data centre (15 megawatts (MW)) uses water as three average-sized hospitals, or more than two 18-hole golf courses. Progress has been made with using recycled and non-potable water, but from the limited figures available some data centre operators are drawing more than half of their water from potable sources. This has been the source of considerable controversy in areas of water stress and highlights the importance of understanding how data centres use water.
Water use in data centre cooling.
ICT equipment generates heat and so most devices must have a mechanism to manage their temperature. Drawing cool air over hot metal transfers heat energy to that air, which is then pushed out into the environment. This works because the computer temperature is usually higher than the surrounding air. The same process occurs in data centres, just at a larger scale. ICT equipment is located within a room or hall, heat is ejected from the equipment via an exhaust and that air is then extracted, cooled and recirculated. Data centre rooms are designed to operate within temperature ranges of 20–22 °C, with a lower bound of 12 °C. As temperatures increase, equipment failure rates also increase, although not necessarily linearly.
There are several different mechanisms for data centre cooling, but the general approach involves chillers reducing air temperature by cooling water—typically to 7–10 °C—which is then used as a heat transfer mechanism. Some data centres use cooling towers where external air travels across a wet media so the water evaporates. Fans expel the hot, wet air and the cooled water is recirculated. Other data centres use adiabatic economisers where water sprayed directly into the air flow, or onto a heat exchange surface, cools the air entering the data centre. With both techniques, the evaporation results in water loss. A small 1 MW data centre using one of these types of traditional cooling can use around 25.5 million litres of water per year.
Cooling the water is the main source of energy consumption. Raising the chiller water temperature from the usual 7–10 °C to 18–20 °C can reduce expenses by 40% due to the reduced temperature difference between the water and the air. Costs depend on the seasonal ambient temperature of the data centre location. In cooler regions, less cooling is required, and instead free air cooling can draw in cold air from the external environment. This also means smaller chillers can be used, reducing capital expenditure by up to 30%. Both Google and Microsoft have built data centres without chillers, but this is difficult in hot regions.
Alternative water sources
Where data centres own and operate the entire facility, there is more flexibility for exploring alternative sources of water, and different techniques for keeping ICT equipment cool.
Google’s Hamina data centre in Finland has used sea water for cooling since it opened in 2011. Using existing pipes from when the facility was a paper mill, the cold sea water is pumped into heat exchangers within the data centre. The sea water is kept separate from the freshwater, which circulates within the heat exchangers. When expelled, the hot water is mixed with cold sea water before being returned to the sea.
Despite Amazon’s poor environmental efforts in comparison to Google and Microsoft, they are expanding their use of non-potable water. Data centre operators have a history of using drinking water for cooling, and most source their water from reservoirs because access to rainfall, grey water and surface water is seen as unreliable. Digital Realty, a large global data centre operator, is one of the few companies publishing a water source breakdown. Reducing this proportion is important because the processing and filtering requirements of drinking water increase the lifecycle energy footprint. The embodied energy in the manufacturing of any chemicals required for filtering must also be considered. This increases the overall carbon footprint of a data centre.
Amazon claims to be the first data centre operator approved for using recycled water for direct evaporative cooling. Deployed in their data centres in Northern Virginia and Oregon, they also have plans to retrofit facilities in Northern California. However, Digital Realty faced delays when working with a local utility in Los Angeles because they needed a new pipeline to pump recycled water to its data centres.
Microsoft’s Project Natick is a different attempt to tackle this challenge by submerging a sealed data centre under water. Tests concluded off the Orkney Islands in 2020 showed that 864 servers could run reliably for 2 years with cooling provided by the ambient sea temperature, and electricity from local renewable sources. The potential to make use of natural cooling is encouraging, however, the small scale of these systems could mean higher costs, making them appropriate only for certain high-value use cases.
ICT equipment is deployed in racks, aligned in rows, within a data centre room. Traditional cooling manages the temperature of the room as a whole, however, this is not as efficient as more targeted cooling. Moving from cooling the entire room to focused cooling of a row of servers, or even a specific rack, can achieve energy savings of up to 29%, and is the subject of a Google patent granted in 2012.
This is becoming necessary because of the increase in rack density. Microsoft is deploying new hardware such as the Nvidia DGX-2 Graphics Processing Unit that consumes 10 kW for machine learning workloads, and existing cooling techniques are proving insufficient. Using low-boiling-point liquids is more efficient than using ambient air cooling and past experiments have shown that a super-computing system can transfer 96% of excess heat to water, with 45% less heat transferred to the ambient air. Microsoft is now testing these techniques in its cloud data centres.
These projects show promise for the future, but there are still gains to be had from existing infrastructure. Google has used its AI expertise to reduce energy use from cooling by up to 40% through hourly adjustments to environmental controls based on predicted weather, internal temperatures and pressure within its existing data centres. Another idea is to co-locate data centres and desalination facilities so they can share energy intensive operations68. That most of the innovation is now led by the big three cloud providers demonstrates their scale advantage. By owning, managing and controlling the entire value chain from server design through to the location of the building, cloud vendors have been able to push data centre efficiency to levels impossible for more traditional operators to achieve.
However, only the largest providers build their own data centres, and often work with other data centre operators in smaller regions. For example, as of the end of 2020, Google lists 21 data centres, publishes PUE for 17, but has over 100 points of presence (PoPs) around the world. These PoPs are used to provide services closer to its users, for example, to provide faster load times when streaming YouTube videos. Whilst Google owns the equipment deployed in the PoP, it does not have the same level of control as it does when it designs and builds its own data centres. Even so, Google has explored efficiency improvements such as optimising air venting, increasing temperature from 22 to 27 °C, deployed plastic curtains to establish cool aisles for more heat sensitive equipment and improved the design of air conditioning return air flow. In a case study for one its PoPs, this work was shown to reduce PUE from 2.4 to 1.7 and saved US$67,000 per year in energy for a cost of US$25,000.
References
Data Centre Types Explained in 5 Minutes or Less (geekflare.com)
Data centre water consumption | npj Clean Water (nature.com)
Drought-stricken communities push back against data centres (nbcnews.com)
Our commitment to climate-conscious data centre cooling (blog.google)
Water Usage Effectiveness For Data Centre Sustainability – AKCP